LINKEDIN SQL DATA CLEANING -MySQL (Click to view full SQL script here)
There is a wide gap between raw data and successful data analysis. Data Cleaning bridges this gap, hence the reason why it is an important pre-requisite for a successful data analysis.
Data Cleaning (or Data Cleansing) refers to the process of identifying incomplete, incorrect, inconsistent, inaccurate or irrelevant parts of the data and then replacing, modifying or deleting the dirty / coarse data. Insights are only as good as the data that informs them, as a result, clean data is more likely to inform good insights.
This project is a step-by-step walkthrough of the process used in Cleaning a data about various Job posts on Linkedin around the globe mainly for year 2023. The data is publicly available on www.kaggle.com. Using the table data import wizard, the dataset was imported to MySQL workbench and found to contain 31.597 rows of data and 9 field columns.
A LOOK AT DATASET
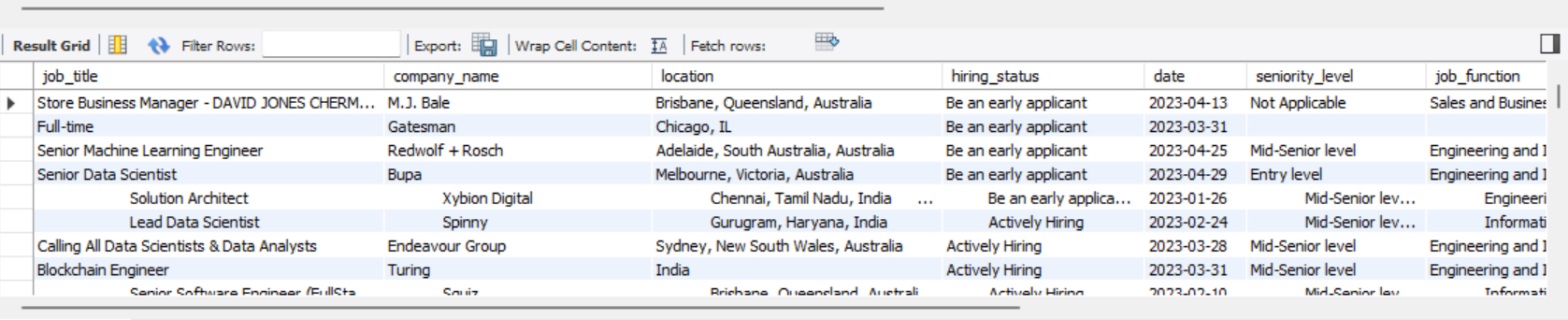
Relevant columns for the analysis were identified and the steps were taken to improve their usability and ensure they are error free.
Click to view full SQL script here
SOME IMPORTANT QUERIES
- Removing irrelevant spaces and characters from columns - The data has lots of irrelevant white spaces and some other inconsistent characters in them. Trim function along with replace was used to clear all the inconsistencies.

- Splitting column - The location was split into 3 columns of city, state, country for better analysis. Substring_Index function was used to split columns

- Formatting date column - The date column was converted from text format to date format using str_to_date function and then altering table to convert text to date format.
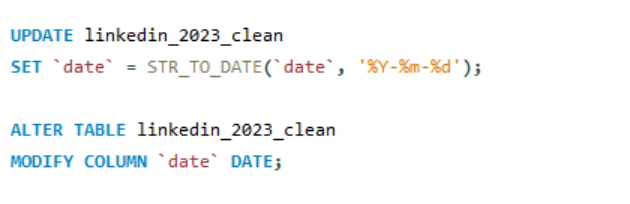
- Dealing with nulls - Every column had some nulls in the data, each column was dealt accordingly. Here is the one example of treating nulls.

- Removing Duplicates- The data had lots of duplicates so the query was written using CTE and windows function to delete duplicate values.

After all the steps the dataset is now ready for further analysis and can be used to derive meaningful insights about job postings on LinkedIn. This project demonstrates the importance of data cleaning in ensuring data quality and reliability.
DATA EXPLORATION:
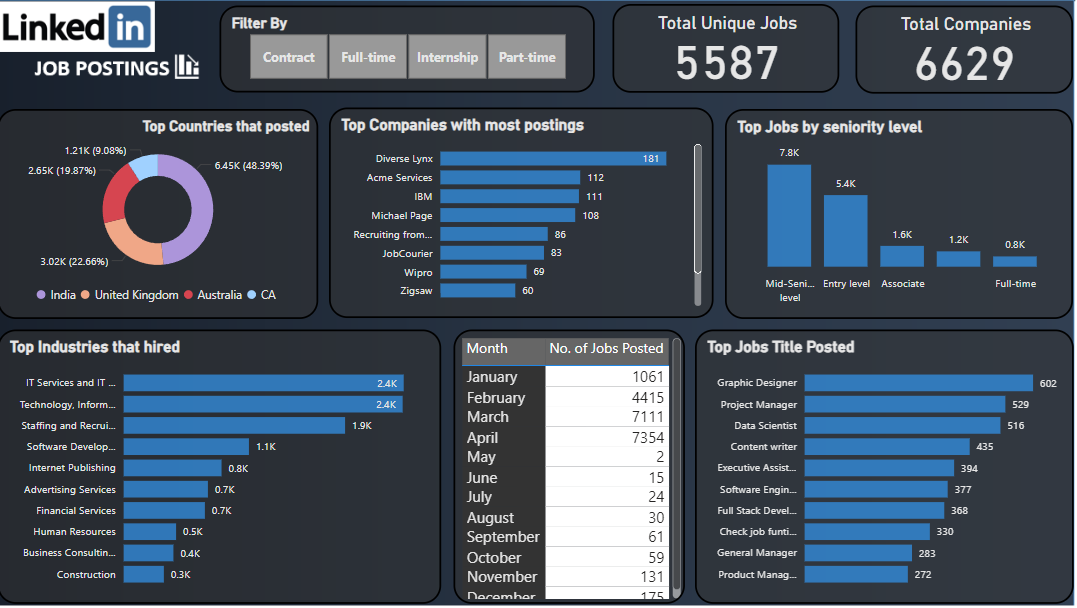
After performing the necessary data cleaning steps the dataset was used to perform exploratory data analysis. Various insights regarding highest job title, company with highest job posted, industry with most jobs were derived using grouping and aggregating queries.
The data was then taken into Power bi for different analysis functions. Many insights were found regarding the data and was built into a report.
A GLIMPSE OF THE REPORT PAGE